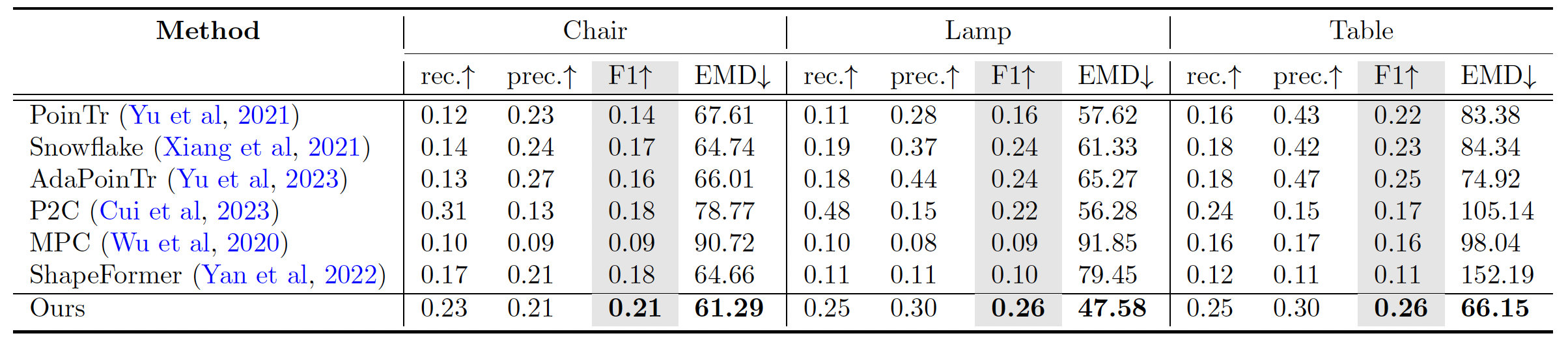
Abstract
Point cloud completion aims to recover the complete 3D shape of an object from partial observations. While approaches relying on synthetic shape priors achieved promising results in this domain, their applicability and generalizability to real-world data are still limited. To tackle this problem, we propose a self-supervised framework, namely RealDiff, that formulates point cloud completion as a conditional generation problem directly on real-world measurements.
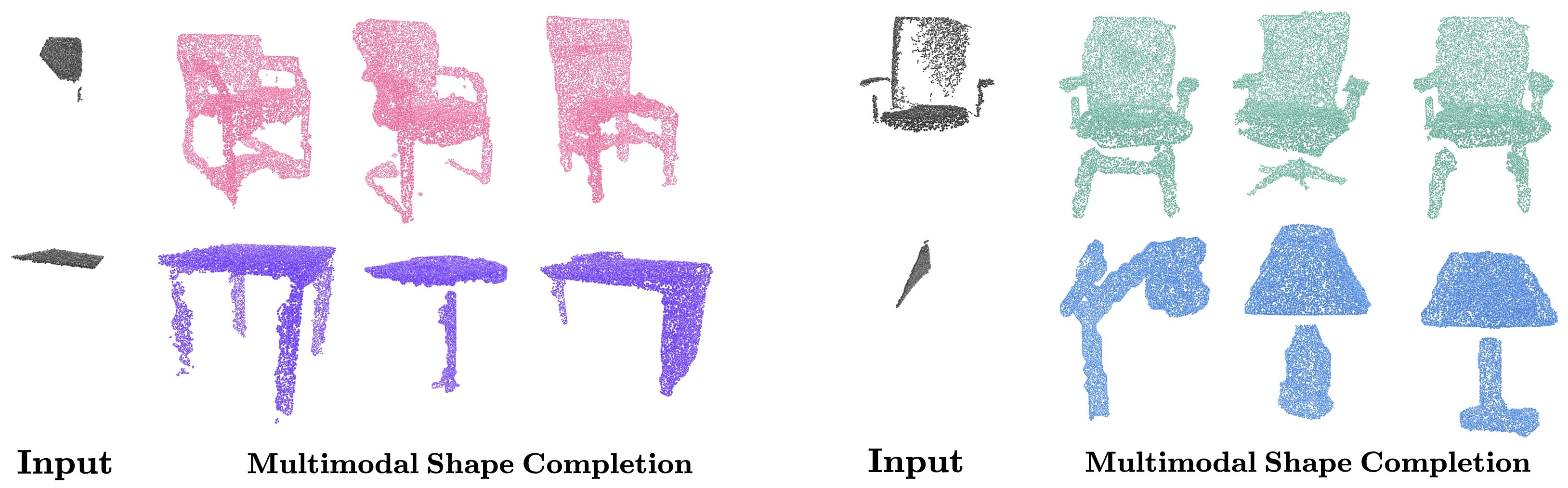
To better deal with noisy observations without resorting to training on synthetic data, we leverage additional geometric cues. Specifically, RealDiff simulates a diffusion process at the missing object parts while conditioning the generation on the partial input to address the multimodal nature of the task. We further regularize the training by matching object silhouettes and depth maps, predicted by our method, with the externally estimated ones. Experimental results show that our method consistently outperforms state-of-the-art methods in real-world point cloud completion.
Overview
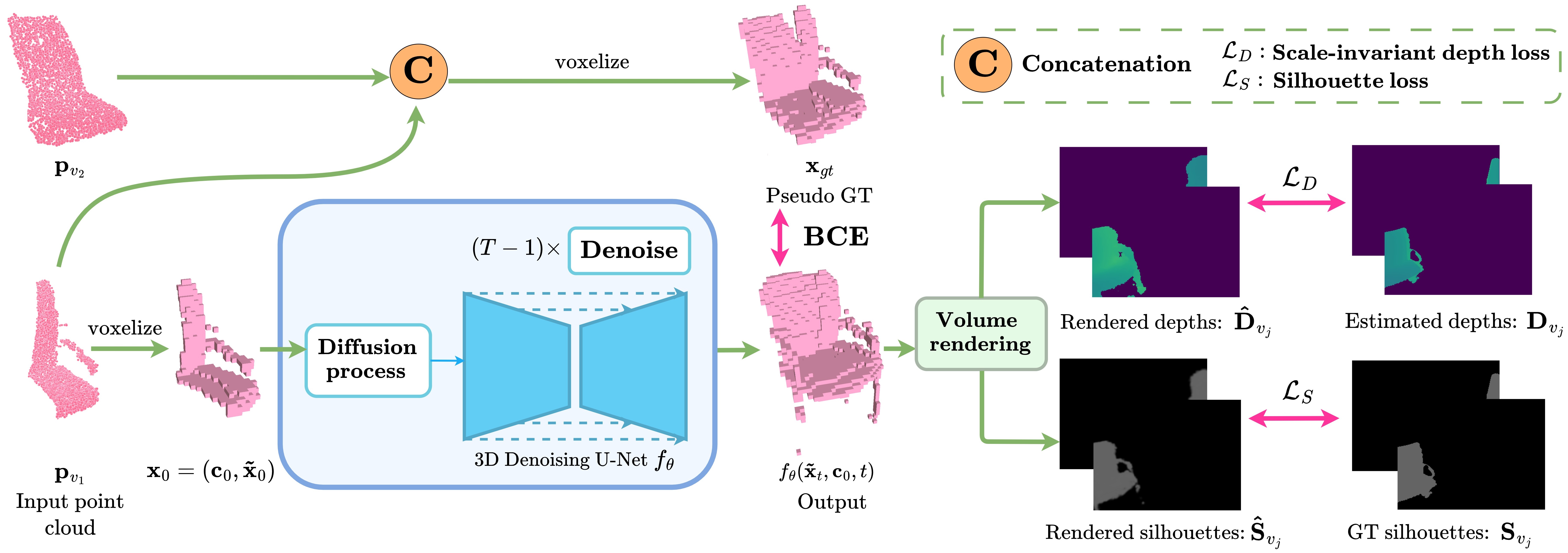
When given a pair of noisy point clouds representing an object, our pipeline takes one of these point clouds as input, and a pseudo ground-truth is created by combining the two point clouds. A diffusion process is simulated at the missing parts (unoccupied input voxels) of the voxelized input, while conditioning the generation on the known parts (occupied input voxels). To eliminate the noise from the reconstructions, the rendered object shapes’ silhouettes and depth maps are constrained to match the auxiliary silhouettes (e.g. from ScanNet) and depth maps (e.g., from a pre-trained Omnidata model). At generation time, only fθ is used to reconstruct a complete 3D shape from the input real-world point cloud.